Crunch Node Introduction (5:48)
What a Crunch Node does
In practice, your node handles four responsibilities:- Data ingestion — collect or host the data your competition needs (market feeds, datasets, APIs)
- Model orchestration — send data to connected models, trigger training and inference, and collect predictions
- Scoring — evaluate predictions against ground truth using your scoring function, aggregate results, and build a leaderboard
- Reporting — expose results via API so the dashboard, participants, and external systems can consume them
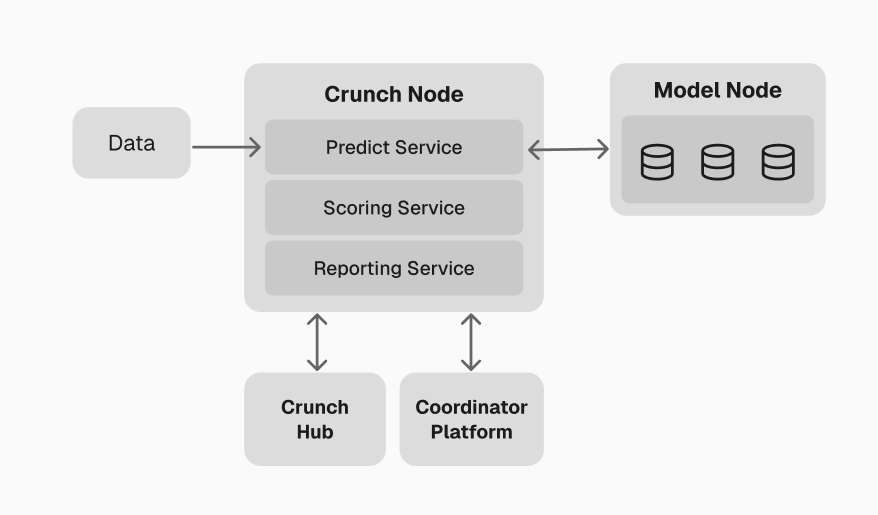
Typical Crunch Node setup showing the four responsibilities
Infrastructure requirements
You are responsible for hosting your Crunch Node and everything around it: which data to use, when to trigger calls, how to compute scores, and how to produce results. A simple cloud server or on-premises machine is usually enough. The required capacity depends primarily on what you do around predictions — ingestion, scoring, aggregation, and storage. You do not need to size infrastructure for model execution. Models are deployed, scaled, and managed by Crunch Labs through the Model Nodes.The
crunch-node package provides a production-ready engine with all four responsibilities
built in. You configure behavior through environment variables and a CrunchConfig. See the
Getting started guide.Next: Model Nodes
Understand the managed infrastructure that executes participant models securely.