condorgame_backend in
the local environment or on
GitHub) and
demonstrates how to build and deploy a real-time crypto price prediction competition.
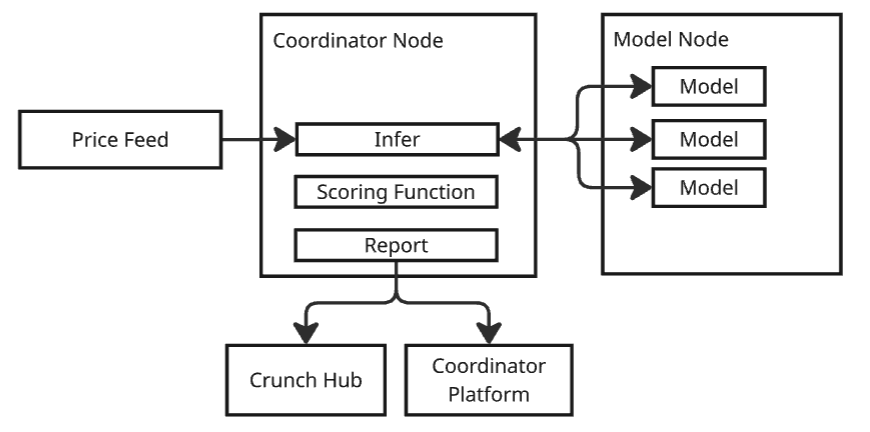
The Condor Game backend consists of three independent services that work together to orchestrate the
competition. This separation ensures that real-time prediction gathering, compute-intensive scoring,
and public reporting can scale independently.
Node Services
The Coordinator Node Starter Kit provides a complete implementation of the Coordinator Node services. The services are:- Infer Service - Collects predictions in real-time
- Score Service - Evaluates predictions and generates rankings
- Report Service - Exposes HTTP API for seeing results locally or making them available to the Public on the Crunch Hub
More details on how your node will call the models can be found in the Model Runner
documentation and in the upcoming section which defines the interface of the base model.
Predict Service
Purpose: Real-time orchestration and prediction collection The Predict Service (/services/predict_service.py)
coordinates all participant models in real-time, keeping them synchronized with market data and
collecting their predictions.
Core Functions
The service continuously performs these operations:
- Market data synchronization - Fetches latest market data and broadcasts tick updates to all connected models
- Model state management - Maintains an up-to-date registry of connected models with their metadata (cruncher name, model name, deployment ID)
- Prediction collection - Triggers scheduled prediction calls to all models for specified assets and time horizons
- Persistence - Stores all raw predictions for asynchronous scoring
For details on model connection and request handling, see the Model Runner
documentation.
Score Service
Purpose: Compute model performance and rankings The Score Service (/services/score_service.py)
transforms raw predictions into scores and leaderboard rankings. It operates independently from the
Predict Service, allowing CPU-intensive scoring operations to run without impacting real-time
prediction collection.
Core Functions
The service performs these operations continuously:
- Ground truth management - Maintains a local cache of realized prices for evaluation
- Prediction resolution - Fetches predictions that are ready to be scored (where the future outcome is now known)
- Likelihood scoring - Evaluates each prediction using the
density_pdfmethod to compute log-likelihood scores - Model aggregation - Combines individual prediction scores into model-level metrics (recent, steady, anchor, and overall scores)
- Leaderboard generation - Ranks all models based on their overall performance and stores results for consumption by the Report Service
- Data pruning - Removes old predictions and snapshots to prevent unbounded storage growth
Scoring Methodology in Detail
Scoring Methodology in Detail
The scoring system evaluates predictions in two stages:
1. Individual Prediction Scoring
For each submitted prediction:- Validation - Verify the prediction succeeded and returned the expected number of distributions (one per time step)
- Price resolution - Retrieve the realized prices closest to each prediction timestamp
- Log-return calculation - Compute the actual log-return that occurred
- Likelihood evaluation - Evaluate the predicted probability density at the realized log-return
using the
density_pdffunction - Aggregation - Average the likelihood values across all time steps
PredictionScore object containing the score value and success status.2. Model-Level Aggregation
After individual predictions are scored, the service computes model-level performance metrics:- Score retrieval - Query windowed prediction scores from storage (optimized for performance)
- Metric computation - Calculate three types of scores for each model:
- Recent score - Performance over the most recent time window (detects current form)
- Steady score - Medium-term performance (balances recency and stability)
- Anchor scores - Performance breakdown by parameter set (asset, horizon, step combinations)
- Overall scoring - Combine the component scores into a single overall performance metric
- Persistence - Save updated model scores and create periodic snapshots for historical analysis
- Cleanup - Prune old snapshots to manage storage
Report Service
Purpose: Public API for competition results and analytics The Report Service (/workers/report_worker.py)
provides the HTTP API layer for accessing competition data. By separating reporting from prediction
and scoring, the system ensures that public API traffic never impacts the real-time competition
pipeline.
It provides the following API endpoints:
Current Leaderboard
model_id- Unique identifier for each modelrank- Current position in the competition- Score components:
score_recent,score_steady,score_anchor created_at- Timestamp when the leaderboard was generated
projectIds(required) - List of model IDs to retrieve metrics forstart(required) - Start datetime of the requested time windowend(required) - End datetime of the requested time window
- Overall score components:
score_recent,score_steady,score_anchor performed_at- Timestamp when the snapshot was computed
projectIds(required) - List of model IDs to retrieve metrics forstart(required) - Start datetime of the requested time windowend(required) - End datetime of the requested time window
(asset, horizon, step) combination:
- Parameter identifier (e.g., “BTC, 24h horizon, 5min step”)
- Score components:
score_recent,score_steady,score_anchor performed_at- Timestamp when the snapshot was computed
projectIds(required) - Single model ID only (multiple IDs are rejected)start(required) - Start datetime of the requested time windowend(required) - End datetime of the requested time window
- Parameter set:
asset,horizon,step - Score information:
score_valueor failure details (score_failed,score_failed_reason) - Timestamps:
performed_at(when predicted),scored_at(when evaluated)